【Pythonマニアック編】yieldとは何か?イテレータとジェネレータでforループを真に理解する
公開日: 2025年11月10日
Pythonを学んだ誰もが、ごく自然にforループを使います。for item in my_list:と書けば、リストの要素が順番に取り出せる。それは当たり前のことだと感じていますよね。 しかし、その「当たり前」の裏側で、Pythonがどのような仕組みを動かしているのか、考えたことはありますか?
なぜ、listだけでなくange()やdict.items()もforループで回せるのか? その答えの鍵を握るのが、「イテレータプロトコル」というPythonの根幹をなすルールです。
今日は、この少しマニアックな世界に足を踏み入れます。 forループの真の姿を理解し、そして、ジェネレータとyieldというキーワードを使いこなすことで、メモリ効率を劇的に改善し、さらには「無限のデータ」さえも扱える、プロフェッショナルなコードの書き方を学びましょう。
🤔 forループの裏側:イテレータプロトコル
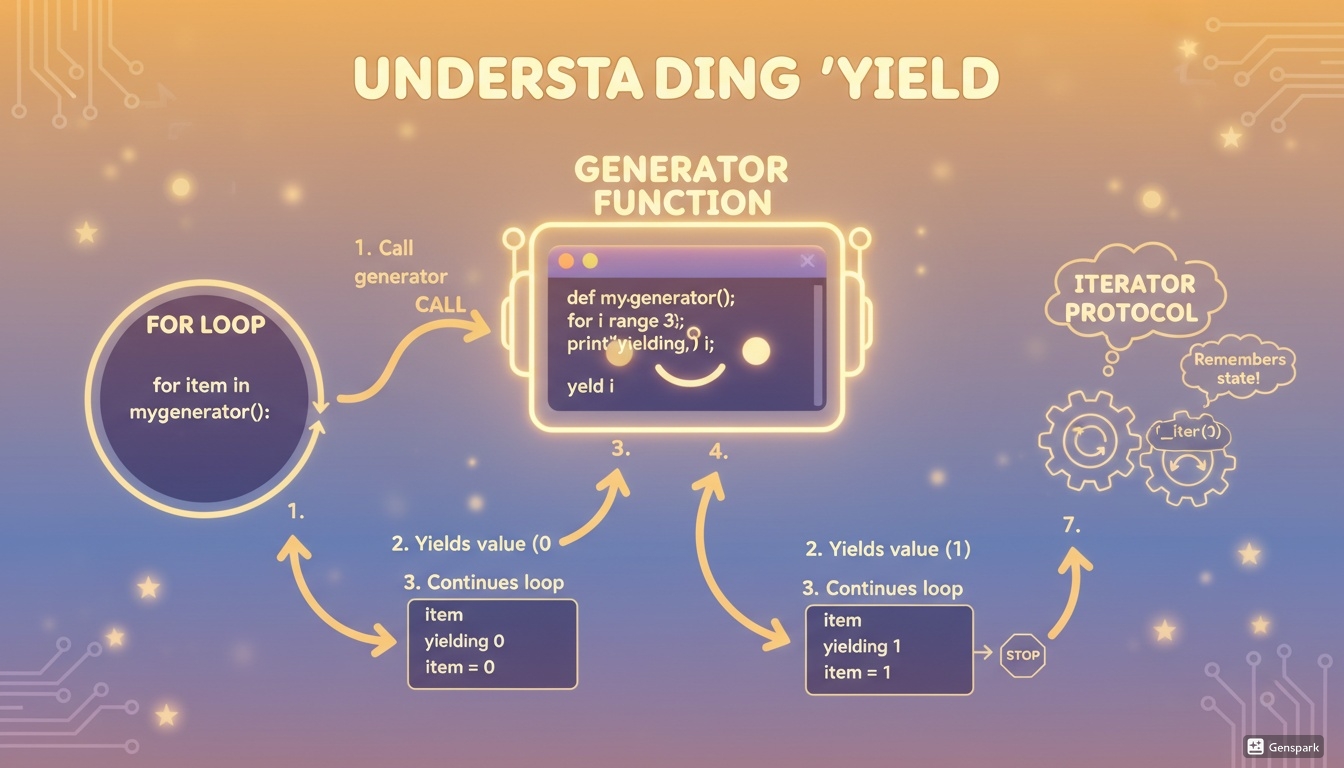
Pythonのforループは、実は以下のような処理を裏側で自動的に行っています。
- ループの対象(例:my_list)から、イテレータオブジェクトを取り出す。(iter(my_list)が呼ばれる)
- そのイテレータオブジェクトに対して、「次の要素をください」と繰り返し要求する。(next()が呼ばれる)
- 要求されたイテレータが、「もう次はありません」と合図(StopIteration例外)を出すまで、2を繰り返す。
このiter()とnext()という2つのルール(プロトコル)に従っているオブジェクトであれば、何でもforループの対象にできるのです。
メモリ問題:もし1億個の数字リストが必要なら?
ここで、一つの問題を考えてみましょう。「1から1億までの数字の2乗の合計を計算したい」とします。 多くの初心者は、まずリストを作ろうと考えるでしょう。
# やってはいけない、メモリを爆食いするコード
numbers = []
for i in range(1, 100_000_001):
numbers.append(i)
# この時点で、1億個の整数を格納した巨大なリストがメモリ上に確保されてしまう!
# メモリが足りなければ、PCはフリーズする。
# squares = [x*x for x in numbers] # さらに巨大なリストが...
# total = sum(squares)
合計を計算したいだけなのに、なぜ最初に1億個もの数字をすべてメモリに溜め込む必要があるのでしょうか? 「最初の数字を2乗して、次の数字を2乗して足して、その次を…」と、一つずつ処理していけば、巨大なリストは不要なはずです。
💡 解決策:ジェネレータとyieldの魔法
この問題を解決するのがジェネレータです。 ジェネレータとは、イテレータを自動で作成してくれる、特殊な関数のこと。 そして、そのジェネレータを作るためのキーワードがyieldです。
yieldは、returnによく似ていますが、その動きは全く異なります。 - return: 関数を完全に終了し、値を返す。 - yield: 一時的に値を返し、関数の状態を記憶したまま、そこで一時停止する。そして、次にnext()で呼ばれた時に、その停止した場所から処理を再開する。
ジェネレータ関数で、巨大なデータストリームを作る
1から1億までの数字を「生成」するジェネレータ関数を書いてみましょう。
def one_hundred_million_generator():
print("ジェネレータを開始します...")
for i in range(1, 100_000_001):
yield i # ここで値を返し、一時停止する
print("...ジェネレータが終了しました。")
# ジェネレータ関数を呼び出すと、ジェネレータオブジェクトが返る
# この時点では、まだ関数の中身は一切実行されない!
gen = one_hundred_million_generator()
# forループで初めて、一つずつ値が生成されていく
total_square = 0
for number in gen:
total_square += number * number
# メモリ上には、常に一つの'number'しか存在しない!
print(f"合計値: {total_square}")
メモリ効率の革命
このコードでは、1億個の数字リストはどこにも存在しません。forループが「次の数字ちょうだい」と要求するたびに、ジェネレータはyield iで一つだけ数字を返し、次の要求が来るまで眠りにつきます。
これにより、使用するメモリ量をほぼゼロに抑えたまま、巨大なデータ処理が可能になるのです。
🤖 AIにyieldの動きを「実況中継」させる
yieldの「一時停止して再開する」という動きは、従来の関数の常識とは異なるため、最初はイメージを掴むのが難しいかもしれません。 yieldを含むジェネレータ関数や、next()を直接使うようなコードは、初心者にとってまさに「魔法のコード」に見えるでしょう。
そんな時こそ、AIコード解説ツール「SerchCode Pro」の出番です。 ジェネレータ関数をツールに貼り付け、「プロ向け」の解説をリクエストしてみてください。 AIは、このコードが単なる関数ではなく、状態を保持する「ステートフル」なジェネレータであることを解説してくれます。 そして、forループやnext()によって、yieldの行がどのように何度も実行され、そのたびにiの値がどのように変化していくかを、プログラムの実行をシミュレートするように、順を追って説明してくれます。 AIの解説は、この難解な概念を理解するための、最高の「可視化ツール」となるのです。
まとめ:なぜプロはジェネレータを愛するのか?
ジェネレータとyieldは、単なるマニアックな機能ではありません。それは、Pythonが持つ「遅延評価(lazy evaluation)」という思想を体現した、非常に実践的なツールです。
- メモリ効率の最大化: 巨大なデータセットを扱う際に、メモリ使用量を劇的に削減できる。
- 無限データストリームの表現:** センサーデータや株価情報など、終わりがない「無限の」データを扱うプログラムも、ジェネレータを使えばエレガントに記述できる。
- コードの可読性: データの前処理パイプラインなどを、yieldを使ってシンプルで読みやすい関数として表現できる。
`for`ループの裏側にあるイテレータの仕組みと、yieldがもたらす遅延評価の力を理解した時、あなたのPythonコードは、単に「動く」だけのものから、パフォーマンスと美しさを兼ね備えた、真にプロフェッショナルなものへと進化するでしょう。
プログラミング学習に必須ツール!
記事で紹介したコードがよく分からなかったり、ご自身のコードについてもっと知りたい場合は、AIコード解説ツールが便利です。コードを貼り付けるだけで、AIが日本語で分かりやすく解説します。
AIコード解説ツールを使ってみる →